23 Jan 2015
OK. Please stop laughing. It's a
thing now.
Seriously though, it's my little project of writing a major mode for
Emacs. I've written many minor modes, but this is my first major
one. Granted, it's only a small derivation of emacs-lisp-mode.
How the ElTeX looks like
Here's how a sample document outline looks like:
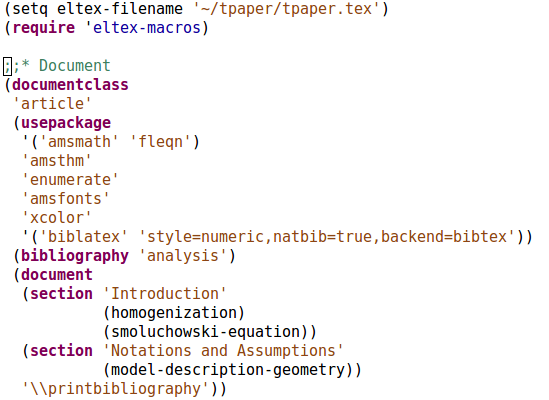
Here, homogenization, smoluchowski-equation, and
model-description-geometry are simply Elisp functions that should
produce a string on call. They are defined here.
On calling M-x eltex-compile, the corresponding LaTeX
document will be written to the file to which eltex-filename points
to.
How the corresponding LaTeX looks like
Here's an excerpt of what will be generated:
\documentclass{article}
\usepackage[fleqn]{amsmath}
\usepackage{amsthm}
\usepackage{enumerate}
\usepackage{amsfonts}
\usepackage{xcolor}
\usepackage[style=numeric,natbib=true,backend=bibtex]{biblatex}
\addbibresource{analysis.bib}
\begin{document}
\section{Introduction}
\subsection{Homogenization}
How the original ElTeX looks like in emacs-lisp-mode
(setq eltex-filename "~/tpaper/tpaper.tex")
(require 'eltex-macros)
;;* Document
(documentclass
"article"
(usepackage
'("amsmath" "fleqn")
"amsthm"
"enumerate"
"amsfonts"
"xcolor"
'("biblatex" "style=numeric,natbib=true,backend=bibtex"))
(bibliography "analysis")
(document
(section "Introduction"
(homogenization)
(smoluchowski-equation))
(section "Notations and Assumptions"
(model-description-geometry))
"\\printbibliography"))
Why this?
Well, why not? At one point I was frustrated with LaTeX not allowing
me to define mathematically rich entities. I did hack up a few TeX
macros for this eventually, but it was very awkward.
So I thought that I could make Emacs Lisp generate simple LaTeX in a
similar way that C generates machine code. No more intricate LaTeX
macros, only plain LaTeX, generated from (intricate) Elisp.
This is still very much in a toy stage, I don't currently use it for
anything serious. Still, in case you're interested in defining
derived major modes, you can look at my
implementation,
it's only 25 lines. The interesting thing about it, if you noticed, is
that it replaces all double quoted strings visually with single quoted
strings, so that they don't jump out as much.
More examples
Here's how the typesetting of some mathematical logic looks like:

And here's the corresponding LaTeX:

Note how simple the resulting LaTeX is, considering how many variables
were used to generate it. Now, I can update anything in the with
Elisp binding, and the corresponding LaTeX will be appropriately
regenerated, error-free.
22 Jan 2015
I just wanted to highlight my latest
submission to emacs-devel.
The patch
The attached
patch,
together with the macro
short-lambda will add a
shorthand for defining lambdas in Emacs Lisp.
Here's an excerpt from the Clojure reader docs
Anonymous function literal (#())
#(...) => (fn [args] (...))
where args are determined by the presence of argument literals
taking the form %, %n or %&. % is a synonym for %1, %n designates
the nth arg (1-based), and %& designates a rest arg. This is not a
replacement for fn - idiomatic used would be for very short one-off
mapping/filter fns and the like.
#() forms cannot be nested.
What the patch does
It makes it possible to write this in Elisp:
(mapc #(put % 'disabled nil)
'(upcase-region downcase-region narrow-to-region))
You can also do this and other things that you would expect, if you're
familiar with Clojure:
(cl-mapcar #(concat %1 " are " %2)
'("roses" "violets")
'("red" "blue"))
;; => ("roses are red" "violets are blue")
Or you could replace this snippet from org-mode's code:
(mapcar (lambda (x)
(and (member (car x) matchers) (nth 1 x)))
org-latex-regexps)
with this sugar-coated code:
(mapcar #(and (member (car %) matchers) (nth 1 %))
org-latex-regexps)
Outro
I hope that this gets accepted, although there are some conservative
people that protest against this change. Let me know if you would
like to have this option for your Elisp setups. And remember that you
can try out the patch if you're familiar with
building Emacs from source.
21 Jan 2015
I've posted about dired quite a few times now. Below, I'll do a
short review of the old bindings and add a few remaining recipes from
my dired.el.
Old stuff
- Binding r to
dired-start-process is covered here.
- Binding e to
ediff-files is mentioned here.
- Binding z to
dired-get-size is covered here.
- Binding ` to
dired-open-term is covered here.
Jump to a file with ido
(define-key dired-mode-map "i" 'ido-find-file)
I use this one quite frequently: i is somehow mnemonic to
C-i, which means completion. Remember that you can select
the current candidate with C-m and the current text
(usually to create a new file) with C-j.
Move up and down
(define-key dired-mode-map "j" 'dired-next-line)
(define-key dired-mode-map "k" 'dired-previous-line)
As I've mentioned before, this is my standard recipe for all modes
that don't self-insert.
Flag garbage files
(define-key dired-mode-map (kbd "%^") 'dired-flag-garbage-files)
Huh, I always thought this was the default binding. I have no idea
where this came from, but I use this plus x to get rid of
the garbage produced by a LaTeX run:
(setq dired-garbage-files-regexp
"\\.idx\\|\\.run\\.xml$\\|\\.bbl$\\|\\.bcf$\\|.blg$\\|-blx.bib$\\|.nav$\\|.snm$\\|.out$\\|.synctex.gz$\\|\\(?:\\.\\(?:aux\\|bak\\|dvi\\|log\\|orig\\|rej\\|toc\\|pyg\\)\\)\\'")
Emacs' adaptation of find
(define-key dired-mode-map "F" 'find-name-dired)
This little function is essential if you want to do perform some
operation on all files in the current directory and its sub
directories that match a pattern. Basically the same thing that you
would do with the UNIX find, just better.
Ignore unimportant files
(define-key dired-mode-map (kbd "M-o") 'dired-omit-mode)
This will toggle the display of unimportant files, like:
(setq dired-omit-files "\\(?:.*\\.\\(?:aux\\|log\\|synctex\\.gz\\|run\\.xml\\|bcf\\|am\\|in\\)\\'\\)\\|^\\.\\|-blx\\.bib")
Move to the parent directory
(define-key dired-mode-map "a"
(lambda ()
(interactive)
(find-alternate-file "..")))
There probably is a default function that does this. I've been using
this one for years, probably because it reuses the current dired
buffer of opening the parent directory.
Outro
Phew, that's a lot of bindings. I don't necessarily encourage you to
use the same bindings as me; I just want to bring your attention to
some of these functions, so that you can work them into your workflow.
If you notice that I'm using some obsolete stuff, do let me know, I'm
always looking to improve.
20 Jan 2015
I managed to spike a lot of interest for sticky key bindings in my earlier post,
Zoom in/out with style.
So now, I've refactored this method into a convenient library
hydra.el.

The Concept
This package can be used to tie related functions into a family of
short bindings with a common prefix - a Hydra.
Once you summon the Hydra through the prefixed binding (the body + any
one head), all heads can be called in succession with only a short
extension.
The Hydra is vanquished once Hercules, any binding that isn't the
Hydra's head, arrives. Note that Hercules, besides vanquishing the
Hydra, will still serve his orignal purpose, calling his proper
command. This makes the Hydra very seamless, it's like a minor mode
that disables itself auto-magically.
An Example
This code will accomplish the task of the previous post:
(require 'hydra)
(hydra-create "<f2>"
'(("g" text-scale-increase)
("l" text-scale-decrease)))
Now, <f2> is the Hydra's body: you need to press it
only once, together with one of the heads (g or
l), to summon the Hydra.
Afterwards, you can call the heads in succession without the body
prefix, i.e. <f2> g g g l will work. To vanquish the
Hydra, just call up Hercules: any key binding that's not
g or l, e.g. C-f or whatever you
wanted to do.
Note that you can still assign an unrelated binding to
e.g. <f2> f: the Hydra does not take over
<f2>, only over <f2> l and
<f2> g.
The Infrastructure
hydra-create will create new interactive functions for you with the proper docstrings:
hydra-<f2>-text-scale-increase is an interactive Lisp function.
It is bound to <f2> g.
(hydra-<f2>-text-scale-increase)
Create a hydra with a "<f2>" body and the heads:
"g": text-scale-increase,
"l": text-scale-decrease.
Call the head: text-scale-increase.
An exciting new Hydra: move window splitter
Zooming is old news, Hydra bundles a new application:
(require 'hydra-examples)
(hydra-create "C-M-o" hydra-example-move-window-splitter)
or in the expanded form (equivalent):
(hydra-create "C-M-o"
'(("h" hydra-move-splitter-left)
("j" hydra-move-splitter-down)
("k" hydra-move-splitter-up)
("l" hydra-move-splitter-right)))
This will allow you to move the window splitter, after you issue
C-x 2 or C-x 3 one or more times, with
e.g. C-M-o h h j k j l k l h. You can, of
course, customize both the body and the heads of this Hydra to your
preferences.
The docstrings for this Hydra look more impressive, too:
hydra-C-M-o-move-splitter-up is an interactive Lisp function.
It is bound to C-M-o k.
(hydra-C-M-o-move-splitter-up)
Create a hydra with a "C-M-o" body and the heads:
"h": hydra-move-splitter-left,
"j": hydra-move-splitter-down,
"k": hydra-move-splitter-up,
"l": hydra-move-splitter-right.
Call the head: hydra-move-splitter-up.
Outro
I hope that you enjoy the new library and let me know when you invent
some novel and efficient Hydras. Happy hacking!
19 Jan 2015
The last release was more than a month ago, and there have been more
than 130 commits to master since then. Somehow, I've been dragging my
feet with this release: the (3 pages of)
release notes
were in the draft stage for 10 days now, while I kept committing on
top of them.
Introduction
This project is my vision of efficient LISP editing. According to
Github, I started it more than a year ago, although the initial commit
already contained around 1000 lines of code. After a year, it's more
than 100 interactive commands in 5000 lines of code and 1000 lines of
tests.
Initially, I started the project because, while I wanted to learn
Paredit to get more efficient, I did not want to learn Paredit's
cumbersome bindings. Having established a skeleton that allows to call
Paredit-like commands with plain letters, over time, I've tacked on
anything LISP-related here. In this way, it's very similar to
org-mode, which starts with an outline and TODO skeleton, and then
adds everything else in the world on top of that. Heck, I actually
tacked on org-mode's outline features on top of lispy: when at an
outline, i is equivalent to org-mode's TAB, and
I is equivalent to S-tab.
Among the other packages with which lispy
integrates/cooperates/coexists are: edebug, ediff, eldoc, ert,
outline, semantic, semantic/db, ace-jump-mode, iedit,
delsel, helm, multiple-cursors, fancy-narrow, projectile,
god-mode, auto-complete, company.
Main idea behind lispy
The idea is to have plain letters, like h or r,
call commands instead of self-inserting, but only if the point
position is such that you wouldn't want to self-insert anyway. When
this situation occurs, I like to say "the point is special"; this
shortcut is all over the code and the docs.
This is a bit similar to vi's normal/insert states, but instead of
"holding" the current state in your head, it's visible through just
the point position. And instead of having just the
Esc/i combination to toggle normal/insert state,
you can do it with any command that moves point,
e.g. C-f, or C-a, or even any custom command
that you write. lispy does provide [, ], and
C-3 key bindings for getting into special, but you are free
to use any other binding or command that you want.
For instance, starting from this code and point position (which is already special):
(when (= arg 0)
(setq arg 2000))
you can move to the when statement with h (lispy-right):
(when (= arg 0)
(setq arg 2000))
or you can remove the when statement altogether with r (lispy-raise):
or you can:
- evaluate
(setq arg 2000) statement with e (lispy-eval); the result will be displayed in the echo area; works for multiple LISP dialects
- evaluate and insert with E (
lispy-eval-and-insert); the actual value 2000 will be inserted below the expression
- evaluate and replace with xr (
lispy-eval-and-replace); the expression will be replaced with 2000
- copy the statement to the kill ring with n (
lispy-new-copy)
- delete the statement with C-d (
lispy-delete)
- insert a copy of the statement below with c (
lispy-clone)
- insert 3 copies of the statement below with 3c (
digit-argument, lispy-clone)
- move the statement on the previous line with DEL (
lispy-delete-backward)
- mark the statement with m (
lispy-mark-list)
- mark only
arg with 2m (digit-argument, lispy-mark-list)
- get help for
setq with xh (lispy-describe)
- get help for
arg with 2mxh (digit-argument, lispy-mark-list, lispy-describe)
- copy
2000 to kill ring with 3mn (digit-argument, lispy-mark-list, lispy-new-copy)
- move the statement outside of
when with oh (lispy-other, lispy-left)
- swap
(= arg 0) with (setq arg 2000) with w (lispy-move-up)
- move it back with s (
lispy-move-down)
- put the whole
when expression on one line with hO (lispy-left, lispy-oneline)
- narrow the buffer to current sexp with N (
lispy-narrow)
- widen the buffer with W (
lispy-widen)
- a lot of other things, there are 52 plain letters, after all
Note that in the following code, the point is not special:
(when (= arg 0)
(setq arg 2000))
so if you would type h, it would not call lispy-left, but would insert "h" instead, yielding whhen.
- to get the point into special before
(when, you can use either C-a or [ or C-M-a
- to get the point into special after
arg 0), you can use either C-e or ]
- to get the point into special after
2000)), you can use C-3
Evolution of special
Initially, the special state was only for the point before an open
paren or after a close paren, since you almost never-ever want to
insert characters at those positions. Over time, other point states
were added to special:
- region is active (supersedes
expand-region for LISP
dialects)
- the point is at the start of a comment
- the point is at the start of an outline
Region selection is especially important, since it is super-useful for
manipulating (move, copy, eval, get-help, goto-definition) symbols
inside lists. Since these symbols aren't delimited with parens, the
only way to get to them with special is though region selection.
Happily, region selection will fix the largest source of Paredit
unbalanced paren errors: while using lispy region-manipulating
commands, you can't copy an unbalanced expression, and thus you can't
yank an unbalanced expression. You just have to use m and
M-m instead of C-SPC; and h,
j, k, l, i,
>, and < instead of e.g. C-f and
M-f.
Since there are only 26 lower-case letters and 26 upper-case letters,
the state of the command bindings in lispy quickly turned into
survival of the fittest:
- the commands that were used the most got the priority bindings of
lower case letters on the home row
- the second tier got the other lower-case bindings
- the third tier of commands were put on upper-case letters and on
x + lower-case letters
- the fourth tier of commands are not bound at all, and I'm
considering to obsolete some of them, just to keep things simpler.
ADD: the Annoyance-Driven Development
The other part of evolving and refining the commands, consisted of
noticing small annoyances for when some generic command wasn't working
as intended, or it was working in a sub-optimal way in a certain
situation. After this, I would fix the command and put a test on it,
to make sure that the annoyance does not surface in the future.
Notes on LISP dialects
My priority is Elisp, since that's what I'm using to implement
lispy, but the following dialects are also supported:
To be supported, all a LISP dialect needs is just to use ( or { or
[ as the opening delimiter; and ) or } or ] as the closing
delimiter, no actual adaptations in the lispy code are necessary.
The only thing that needs to be implemented on a per-dialect basis is
the language-specific eval:
- e (
lispy-eval)
- E (
lispy-eval-and-insert)
- xr (
lispy-eval-and-replace)
- xj (
lispy-debug-step-in)
Also, though the jump-to-definition functionality could be implemented
via CEDET, environments like SLIME can do it much better, so
F (lispy-follow) and M-. (lispy-goto-symbol) use the
appropriate environment's facilities. Somehow, I still haven't managed
to implement this for Geiser.
Drinking from the lispy fire hose
I'll get you started with the most basic and composable commands
below. You can find the rest in the
function reference or by just calling
xv (lispy-view-test) on should statements of
lispy-test.el:

In the screenshot above, I start with the code and point position on
the top. Then, after typing miji, I should end up with the
state below: the point and mark position have moved. In this
particular situation, I could follow-up with e to see the
value of auto-mode-alist. Here's how to decipher miji:
- m -
lispy-mark-list: marks current expression
- i -
lispy-tab (mnemonic for indent or inner): marks the car of current expression
- j -
lispy-down (vi shortcut to move down): moves the point and mark down by one sexp, selecting the quoted expression
- i -
lispy-tab: selects the car of the quoted expression, i.e. auto-mode-alist
As you see from the screenshot, I have show-paren-mode always
on. It's even on in the tests visualization!
The most basic lispy commands: the arrows
- h is left
- j is down
- k is up
- l is right
The directions are literal only if you have your code properly
indented, with newlines after each sexp. Otherwise, it may be the case
that j moves literally right, instead of down; still, it's
down figuratively.
arrows like digits
All of them take digit arguments, so that e.g. 5j is equivalent to jjjjj.
h and j maintain the guarantee of not exiting the
current list, so you can use e.g. 99j to move to the last
element, if your list length is smaller than 99.
arrows like regions
When the region is active, the arrows move the mark appropriately with
the point. You can activate and deactivate the region by repeatedly
pressing m.
You can also mark a symbol with M-m
(lispy-mark-symbol). There's no need to be in special for this
command to work. I call these type of bindings global, while the
bindings that only work in special I call local.
arrows like outlines
When located at the outline, j will call
outline-next-visible-heading, and k will call
outline-previous-visible-heading. l will move to the
first list of the outline, while h will jump between the
top-level sexp and the containing outline.
switching to a different side of the expression
Arrows can't do this easily; this can instead be done with
d (lispy-different). Works for lists and regions.
Moving the code instead of moving around the code
The most basic commands are:
- w is
lispy-move-up
- s is
lispy-move-down
These will "hold on" to the current expression while moving it in the
appropriate direction. There's no need to worry to mess up with them,
since they cancel each other out perfectly.
Note that, just like with the arrows, if you don't have an opening or
closing delimiter to "grab", you can mark a symbol M-m to
be in special and use w / s.
Modified arrows can move too
o will modify the arrow keys temporarily, just for one
command, with a minor mode. You can think of it as making the arrows
move the point and the sexp in the usual direction, instead of
moving just the point.
- ol: move current sexp outside of the parent list, forwards
- oh: move current sexp outside of the parent list, backwards
- oj: move current sexp inside the next list, making it the first element
- ok: move current sexp inside the preceding list, making it the last element
Extending or shrinking the current list or region
- > (
lispy-slurp) grows the current list or region in the current direction by one sexp
- < (
lispy-barf) shrinks the current list or region in the current direction by one sexp
Similarly to j and k, these commands maintain
the guarantee of not exiting the parent list, so you can slurp until
the end of the list with e.g. 99>.
Outro
This project is very far from being final, I'm expecting to reach
0.99.0 before getting to 1.0.0. The reason is that the package
aims to build intuition to the point of automation. For each small
step in that direction, every small bug is two steps back, since it
breaks the process of building intuition. So every possible situation
needs to be tested and bugs fixed until the package is finally ironed
out.
While I do appreciate the
stars, actually trying
to do things with lispy and raising
issues would help me a
great deal more. For instance, if you raise an issue like
How can I generate a function call right after the function definition?
I would say to just use 2mcol(:
- mark the function name with 2m
- clone region with c
- move region outside the function body with ol
- wrap the region with parens while deactivating it with (
And this would be a sort of FAQ question / recipe already done there.
Or you could raise an issue like:
Why doesn't F work for Racket?
I would say it's because I haven't implemented it yet, since it was
tricky. But I'll get to it, now that I see that there's some interest
in lispy from Racket users.
