18 Nov 2017
Intro
I think ivy-occur (C-c C-o) is one of the coolest
features in ivy. It allows you
to save your current search into a new buffer. This has many uses:
- get a full overview of all candidates
- many useful modal bindings (q, j,
k, f) and mouse support
- ability to manipulate candidates as text
- save the search for later, with the option to refresh the search with g
- go over candidates as a TODO list, using C-d to remove elements
Everything above works for any ivy-read session. But the most
powerful features come into play when ivy-occur gets customized for
a specific collection.
ivy-occur for grep-like functions
(ivy-set-occur 'swiper 'swiper-occur)
Thanks to this default customization, the resulting *ivy-occur
swiper* buffer is in ivy-occur-grep-mode which inherits from
grep-mode. Additionally, you can use
ivy-wgrep-change-to-wgrep-mode C-x C-q to edit the result
in-place - pressing C-x C-s will save the changes.
Similar customizations are available for counsel-git-grep,
counsel-ag, counsel-rg, and counsel-grep.
ivy-occur for ivy-switch-buffer
(ivy-set-occur 'ivy-switch-buffer 'ivy-switch-buffer-occur)
This makes C-c C-o open your candidates in the powerful
ibuffer, which adds additional info to your buffer list and allows
you to manipulate buffers easily.
For instance, to delete all matching buffers you can do C-c C-o
tD.
The source code is short enough to be included here:
(defun ivy-switch-buffer-occur ()
"Occur function for `ivy-switch-buffer' using `ibuffer'."
(ibuffer nil (buffer-name) (list (cons 'name ivy--old-re))))
The interface is quite simple: ivy-occur is responsible for
generating a new buffer, and the occur function
e.g. ivy-switch-buffer-occur is to fill that buffer with useful
info, based on the current search parameters like ivy-text and
ivy--old-re.
ivy-occur for counsel-find-file-like functions
This is a brand new feature that works for counsel-find-file,
counsel-git, and counsel-fzf (which itself is quite new, thanks to
@jojojames for contributing it).
Since these functions are used to complete file names, we obviously
want ivy-occur to open a Dired buffer.
Example 1
To delete all *.elc files in the current folder do:
- C-x C-f
elc$ C-c C-o tDy.
Example 2
To copy all Org files in a Git project to some directory do:
- M-x
counsel-git org$ C-c C-o tC.
Example 3
To get a list of videos to watch do:
- M-x
counsel-fzf mp4$ C-c C-o.
I can further e.g. mark 3 files with m and use r
to send these 3 files to vlc as a list. See this
post for my dired setup
that makes r work this way.
You can remove some files afterwards with the usual D or
dx. And to redisplay the buffer use g.
Outro
I hope you like the new feature. I had a really good few hours
figuring out how it should work exactly. Please consider joining my
72 patrons to give me the
opportunity to work on Free Software a lot more. Happy hacking!
28 Oct 2017
Intro
Orca is a new Emacs package, an
attempt to refactor my old org-fu
into something that's much more re-usable and easier to get started
with.
Orca functionality
Problem:
When capturing from Firefox using
org-protocol (together with
this addon):
- either I refile each time I capture, which is slow
- or my captures pile up in one place, which is messy
Solution:
- Define rules for where links from certain websites should be captured.
- Allow to capture directly into the current org-mode buffer, since it's likely related to what I'm working with on.
Part 1: Rules example
Here is my example list of configurations:
Corresponding code:
(setq orca-handler-list
'((orca-handler-match-url
"https://www.reddit.com/"
"~/Dropbox/org/wiki/emacs.org" "Reddit")
(orca-handler-match-url
"https://emacs.stackexchange.com/"
"~/Dropbox/org/wiki/emacs.org" "\\* Questions")
(orca-handler-file
"~/Dropbox/org/ent.org" "\\* Articles")))
Part 2: Current buffer example
For example, I'm researching how to implement something with
docker. This means that I have
docker.org open, along with dozens of tabs in the browser.
I can configure to capture into the current org-mode buffer with a *
Tasks heading like this:
(push '(orca-handler-current-buffer "\\* Tasks") orca-handler-list)
Since docker.org has * Tasks, I just click the capture button in
Firefox and follow up with an immediate C-c C-c in Emacs.
The link is already in the right position, no need for an extra refile
step.
Using customize with orca
You can set up the capture rules using M-x
customize-group RET orca RET.
Here's a screenshot:
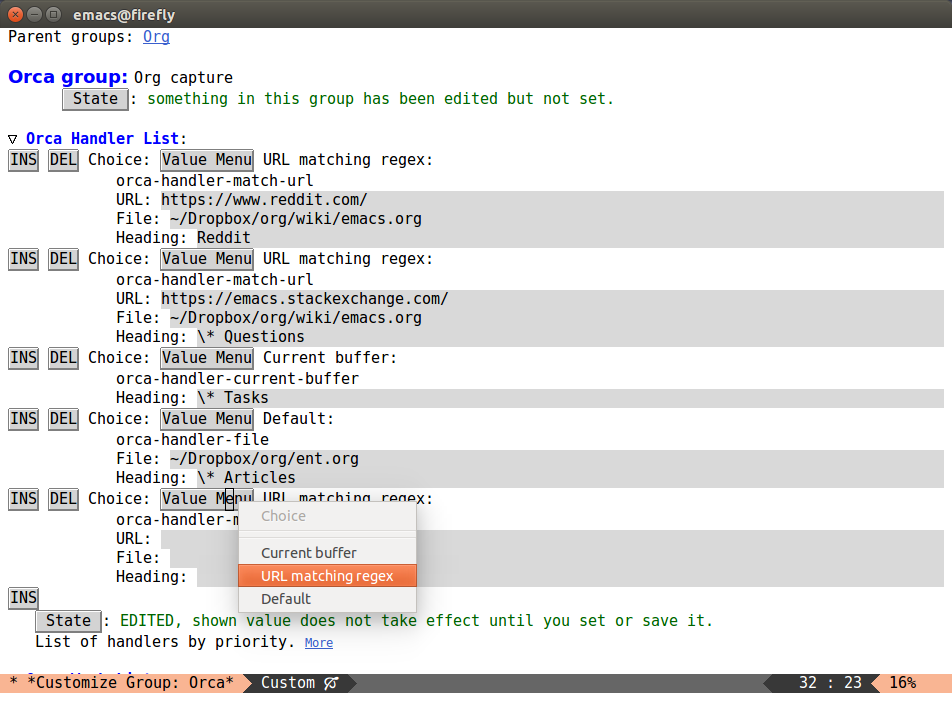
As you see, the customization is a list of an arbitrary length, with
each element falling into one of three categories, each backed by an
Elisp function (orca-handler-current-buffer, orca-handler-file,
and orca-handler-match-url). Each function takes a different number
of arguments (one, two, and three, respectively) - they are all
annotated by the interface.
Here's the code that describes the expected :type to customize:
(defcustom orca-handler-list
;; ...
:type '(repeat
(choice
(list
:tag "Current buffer"
(const orca-handler-current-buffer)
(string :tag "Heading"))
(list
:tag "URL matching regex"
(const orca-handler-match-url)
(string :tag "URL")
(string :tag "File")
(string :tag "Heading"))
(list
:tag "Default"
(const orca-handler-file)
(string :tag "File")
(string :tag "Heading")))))
You can read more about the customization types in this manual section.
Outro
I hope you enjoy orca. I've submitted it to MELPA. Hopefully, it
will be available for an easy install very soon.
Org-mode is a beautiful thing, but my previous attempts to configure
it were huge config files of loosely related (i.e. the only thing in
common was Org-mode) stuff spanning hundreds of lines. Orca is an
improvement in this respect, since it focuses on a very narrow
domain. It still tries to be flexible (just like org-capture) - you
can plug in your own functions into orca-handler-list. But
initially, the flexibility can be constrained into the
customize-group interface, to allow for a self-documenting solution
that's easy to get started with. Happy hacking!
PS. Thanks to all my patrons for advancing my
Patreon campaign!
As of this writing, we're almost at the 25% mark
with 61 contributors.
18 Oct 2017
In light of the recent success of the
Magit Kickstarter
(congratulations to @tarsius, by the way), I got a lot more optimistic about Free Software crowdfunding.
So I opened a Patreon account where you can support my work:
https://www.patreon.com/abo_abo.
The goal I set there is both optimistic and (hopefully) realistic: I'd
like to hack on Free Software 1 day per week indefinitely, reducing my
real world job days to 4 per week.
Ideally, I'd like to work on Free Software full time (one can dream),
but it doesn't look like that level of donations is attainable right
now. But I think I could accomplish a lot working a full day per week:
- improve the level of maintenance of my current projects
- polish and release a few projects I have in a semi-complete unreleased state
- produce more content on my YouTube channel
- maybe start working on an Emacs book
Here's a list of
popular repositories
I've made over the last 5 years in my free time (all Free Software under GPL):
If you are a user of my work, don't feel any pressure to donate. We
are all here voluntarily: I publish because I enjoy it, you use the
software because you find it useful. But out there is the real world,
and, although I like my real world job enough, I can't say that would
I do it voluntarily if I had enough money to meet my needs.
If you do what you love, you'll never work a day in your life
I'd like to do what I love, and I wish you all the same. Happy hacking!
04 Oct 2017
Intro
When creating documents, context aware completion is a powerful
mechanism that can help you improve the speed, correctness and
discoverability.
Emacs provides context aware completion via the complete-symbol
command, bound to C-M-i by default. In order for it to do
something useful, completion-at-point-functions has to be set up.
Documentation:
Special hook to find the completion table for the thing at point.
Each function on this hook is called in turn without any argument and should
return either nil to mean that it is not applicable at point,
or a list of the form (START END COLLECTION) where
START and END delimit the entity to complete and should include
point, COLLECTION is the completion table to use to complete it.
For each major-mode, a different value of
completion-at-point-functions can (and probably should) apply. One
of the modes that's set up nicely by default is emacs-lisp-mode:
press C-M-i to get completion for Elisp variable and
function names. Org-mode, on the other hand, is quite lacking in this
regard: nothing useful happens with C-M-i.
Here's my current setting for Org-mode:
(setq completion-at-point-functions
'(org-completion-symbols
ora-cap-filesystem
org-completion-refs))
org-completion-symbols
When I write about code in Org-mode, I quote items like this:
=/home/oleh/=, =HammerFactoryFactory=, etc.
Quoting has several advantages:
- It looks nice, since it's in a different face,
flyspell doesn't need to check it, which makes sense since it would
fail on most variable and class names,- Prevents Org from confusing directory names for italics mark up.
Completion has one more advantage on top of that: if I refer to a
symbol name multiple times within a document, completion helps me to
enter it quickly and correctly. Here's the corresponding completion
source:
(defun org-completion-symbols ()
(when (looking-back "=[a-zA-Z]+")
(let (cands)
(save-match-data
(save-excursion
(goto-char (point-min))
(while (re-search-forward "=\\([a-zA-Z]+\\)=" nil t)
(cl-pushnew
(match-string-no-properties 0) cands :test 'equal))
cands))
(when cands
(list (match-beginning 0) (match-end 0) cands)))))
First of all, it checks if the point is e.g. after =A, i.e. we
are in fact entering a new quoted symbol. If that's not the case,
return nil and let the other completion sources have a go.
Next, it looks through the current buffer for each =foo= and
=bar=, accumulating them into a list.
Finally, it returns the bounds of what we've got so far, plus the
found candidates. It's important that the bounds are passed to the
completion engine, so that it can delete everything inside the
bounds before inserting the whole selected symbol.
org-cap-filesystem
This source is for completing file names:
(defun ora-cap-filesystem ()
(let (path)
(when (setq path (ffap-string-at-point))
(when (string-match "\\`file:\\(.*\\)\\'" path)
(setq path (match-string 1 path)))
(let ((compl (all-completions path #'read-file-name-internal)))
(when compl
(let* ((str (car compl))
(offset
(let ((i 0)
(len (length str)))
(while (and (< i len)
(equal (get-text-property i 'face str)
'completions-common-part))
(cl-incf i))
i)))
(list (- (point) offset) (point) compl)))))))
I usually enter ~, so that ffap-string-at-point recognizes it as a
path. Then complete each part of the path with C-M-i. It's
very similar to counsel-find-file. In fact, I could just use
counsel-find-file for this, with M-o i to insert the file
name instead of opening the selected file.
org-completion-refs
org-completion-refs is very similar to org-completion-symbols: it
will collect all instances of e.g. \label{foo}, and offer them for
completion when you enter \ref{. If you want to look at the code,
it's available in my config.
Outro
I hope I convinced you about the usefulness of completion at
point. It's especially cool since it's a universal interface for
major-mode-specific completion. So any IDE-like package for any
language could provide its own completion using the familiar
interface. That could go a long way towards providing a "just works"
experience, particularly when dealing with a new language.
04 Aug 2017
counsel-rg
Lately, due to working with a large code base, I've grown more and
more fond of counsel-rg. It's an Elisp wrapper
around ripgrep - a relatively
new recursive grep tool that aims to be faster than the competition
(ag, git grep, pt, ack etc).
Besides being really fast, rg also has some really
nice
command switches.
One such switch is especially useful for Emacs:
-M, --max-columns NUM
: Don't print lines longer than this limit in bytes. Longer lines are omitted,
and only the number of matches in that line is printed.
The -M switch is useful twofold:
- Emacs is slow when dealing with long lines (by long I mean thousands of chars per line)
- Emacs is slow at accepting a huge amount of output from a process
For each character you add to your input, counsel-rg starts a new
shell command to recalculate the matches with the new input. This
means that in order to avoid keyboard lag there's only about 0.1
seconds available for both:
- Running the shell command.
- Accepting output from the shell command.
So I'm quite happy that rg speeds up both steps. Less time spent on
these steps provides for much smoother searching.
counsel-grep-or-swiper
I also work with large log files, one file at a time. For a long time,
I've used counsel-grep-or-swiper as my main search command:
(global-set-key (kbd "C-s") 'counsel-grep-or-swiper)
But for a 40Mb log file with really long lines
counsel-grep-or-swiper started to lag a bit. I tried counsel-rg,
and it was actually faster than grep, although it was searching the
whole directory. So I thought, why not use rg instead of grep? The
switch is actually really easy and required only a simple user
customization:
(setq counsel-grep-base-command
"rg -i -M 120 --no-heading --line-number --color never '%s' %s")
Outro
If you haven't tried ripgrep so far, I suggest you give it a go. Happy hacking!
And if you're a C hacker and have some free time on your hands, why
not look at the long lines and the process output issues in Emacs? I'd
be very grateful:)
