27 Jun 2019
Introduction
When Ivy just started out as a completion framework, the
functionality was supposed to be simple: select one string from a list of strings. The UI is simple
enough:
- Show the list of strings that match the entered text,
- Use C-n and C-p to navigate them,
- Use C-m or C-j to submit.
Emacs has three key bindings that mean "Enter": RET, C-m, and
C-j. But in terminal mode, emacs -nw, RET and C-m are the same
binding: Emacs can't distinguish them. So we have at most two bindings. Fortunately, the world of
completion is simple at the moment, and we only need one binding.
File name completion
Enter file name completion. When you're completing file names, you are selecting not one string, but
many strings in succession while moving from one directory to the next. So we need at least two key
bindings:
- Use C-m (
ivy-done) to select the current candidate and exit completion.
- Use C-j (
ivy-alt-done) to change the current directory to the current candidate without exiting completion.
What to do when C-j is used on a file and not on a directory? Might as well open the
file: same action as C-m. OK, we had two key bindings, and we have used them. Hopefully
nothing else comes up.
Enter creating a new file, i.e. selecting something that's not on the list of strings.
Suppose I call find-file, enter "do", and the only match is a directory named "doc":
- Pressing C-m will end completion with the "doc" directory selected.
- Pressing C-j will continue completion inside the "doc" directory.
So creating a file named "do" is the third action. Our two "Enter" keybindings are already taken by
the first two different useful actions. So we need a third key binding. The one I chose is
C-M-j (ivy-immediate-done). It means: I don't care that the current input is not on
the list of candidate strings, submit it anyway.
Directory creation
Enter directory creation: dired-create-directory and make-directory. These built-in Emacs
commands request file name completion, but what they tell Ivy is no different from what find-file
tells: "I want to select a file". However, for these commands, the C-M-j action is the
one that makes most sense. Here it would be nice for Ivy to take the back seat and just act like an
interactive ls, since the user will enter a completely new string that's not on the list of
candidates.
For a long time, you still had to use C-M-j with those commands, to much frustration of
new but also existing users, including myself. But a few days ago, I looked at the prompt that
dired-create-directory uses: "Create directory: ". That prompt is passed to Ivy. Using the prompt
to detect the intention of the command is a bit of a hack, but I think in this case it's
justifiable. So now Ivy will recognize that the intention commands that request file name completion
and pass the "Create directory: " prompt is to create a directory, and all key bindings will do just
that: C-m, C-j, and C-M-j will behave the same in this case.
An alternative key binding scheme
Note that C-m and C-j behave differently only for directories. But thanks to
the fact that "." is always the first candidate, C-m for directories is equivalent to
C-j C-j. So we can get away with just using ivy-alt-done, and bind C-m to
ivy-immediate-done. Or swap the two meanings:
(define-key ivy-minibuffer-map (kbd "C-j") 'ivy-immediate-done)
(define-key ivy-minibuffer-map (kbd "C-m") 'ivy-alt-done)
The price to pay here is the extra context switch when we simply want to select a directory. We
could the bind ivy-done to C-M-j and avoid the context switch, but then we're back to
three bindings once more. Still, I thought that swapping the bindings is an interesting idea worth
sharing.
Canceling dired-dwim-target
Setting dired-dwim-target is a nice productivity boost. It allows to use Emacs in a similar way to
a two-pane file explorer, like mc(1). But it was really annoying when I was in dir-1 with the
intention to copy a file to a different name in dir-1 (e.g. create a backup, or copy a template),
but the current directory was set to dir-2 because of a random dired window I had open. In that
case, I had to call delete-other-windows, perform the copy, and then restore the window
configuration with winner-undo.
I did the above many times over many years, until I finally dug into the code of dired.el to see
how dired-dwim-target worked. Turns out it was storing dir-1 in the minibuffer-defaults
variable. So now Ivy will use that variable when I press M-n. All in all, it was a five
minute fix. But rather than regret that I didn't do it years ago, I'm glad I did it now. It only
remains to build some muscle memory to press M-n in that situation.
I'm guesstimating that dired-dwim-target works to my advantage 90% of the time when I press
C in dired. For the other 10% of the times, I can now press M-n.
Outro
I hope you find the new functionality useful. I'm always open to new ideas and pull
requests. Happy hacking!
18 May 2019
This release consists of 45 commits done over the course of the last 2 years. With this version, I
have introduced a
Changelog.org,
similar to what ivy and
avy have.

Highlights
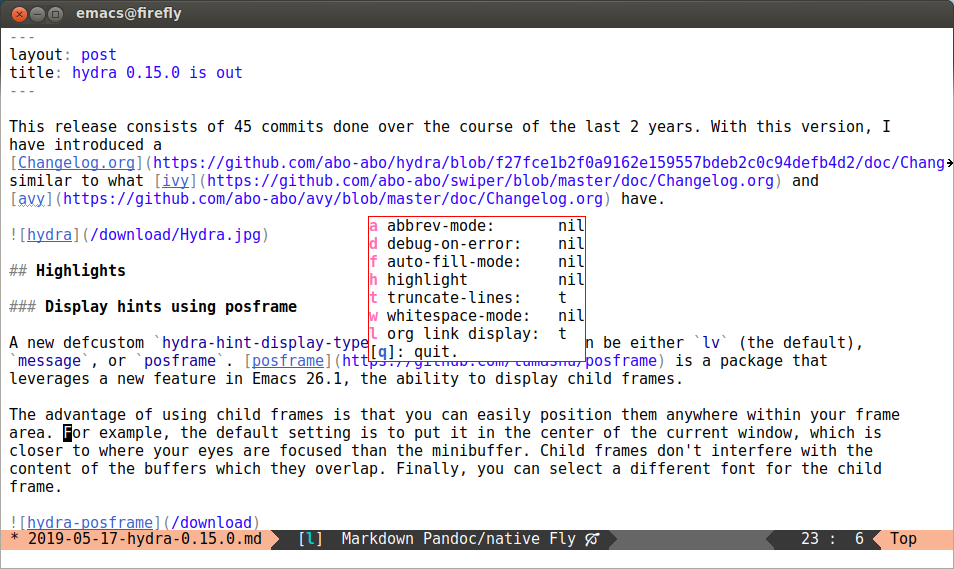
Display hints using posframe
A new defcustom hydra-hint-display-type was introduced that can be either lv (the default),
message, or posframe.
Posframe is a package that leverages a new feature in Emacs
26.1: the ability to display child frames. The advantage of using child frames is that you can
easily position them anywhere within your frame area. For example, the default setting is to put it
in the center of the current window, which is closer to where your eyes are focused than the
minibuffer. Child frames don't interfere with the content of the buffers which they
overlap. Finally, you can select a different font for the child frame.
Less boilerplate in defhydra
You no longer have to add :hint nil, and you can skip the docstring as well:
(defhydra hydra-clock (:exit t)
("q" nil "quit" :column "Clock")
("c" org-clock-cancel "cancel" :column "Do" :exit nil)
("d" org-clock-display "display")
("e" org-clock-modify-effort-estimate "effort")
("i" org-clock-in "in")
("j" org-clock-goto "jump")
("o" org-clock-out "out")
("r" org-clock-report "report"))
Add heads to an existing hydra
You can now add heads to an existing hydra like this:
(defhydra hydra-extendable ()
"extendable"
("j" next-line "down"))
(defhydra+ hydra-extendable ()
("k" previous-line "up"))
The new macro defhydra+ takes the same arguments as defhydra, so it's quite easy to split up or
join your hydras.
The use case of defhydra+ is when you have many packages that want to add heads to an existing
hydra. Some of them may be optional or loaded lazily.
You can now have a base defhydra, and then use defhydra+ to add heads to it when a new package
is loaded. Example:
(defhydra hydra-toggle ()
("q" nil "quit" :column "Exit")
("w" whitespace-mode
(format "whitespace-mode: %S" whitespace-mode)
:column "Toggles"))
(use-package org
:config
(defhydra+ hydra-toggle ()
("l" org-toggle-link-display
(format "org link display: %S" org-descriptive-links))))
Outro
Big thanks to all contributors, and I hope you enjoy the new release. Happy hacking!
PS. Thanks to everyone who supports me on Liberapay and
Patreon!
11 May 2019
This release consists of 109 commits done over the course of the last 3 years by me and many
contributors. Similarly to the 0.4.0
release, the release notes are in
Changelog.org. I recommend
reading them inside Emacs.

Highlights
A lot of new code is just straight upgrades, you don't need to do
anything extra to use them. Below, I'll describe the other part of the
new code, which is new commands and custom vars.
New API functions
New functions have been added as drop-in replacements of double-dash (private) Avy functions that
were used in other packages and configs. Please replace the references to the obsolete functions.
avy-jump is a drop-in replacement of avy--generic-jump,avy-process is a drop-in replacement of avy--process.
New dispatch actions
The concept of dispatch actions was introduced in 0.4.0.
Suppose you have bound:
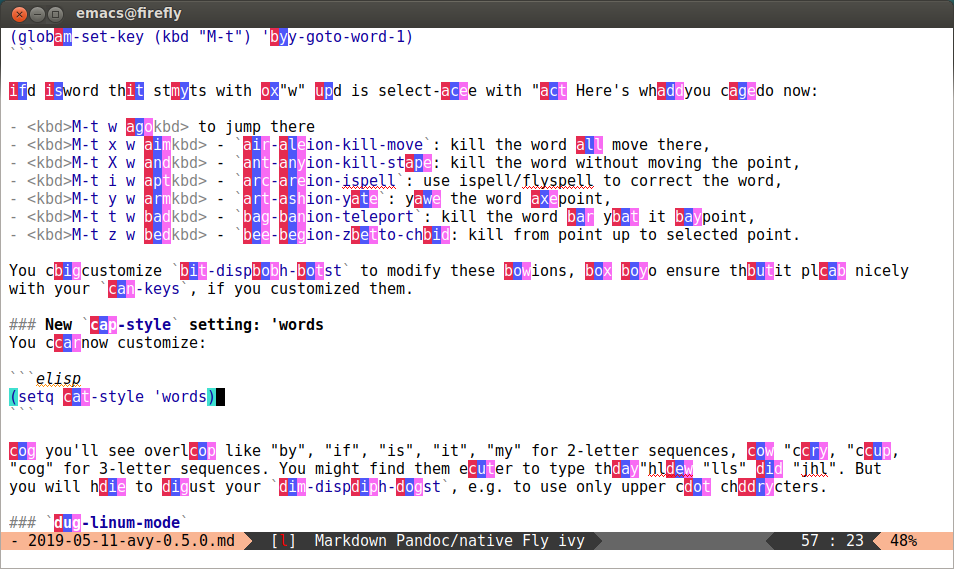
(global-set-key (kbd "M-t") 'avy-goto-word-1)
and a word that starts with a "w" and is select-able with "a". Here's what you can do now:
- M-t w a to jump there
- M-t w x a -
avy-action-kill-move: kill the word and move there,
- M-t w X a -
avy-action-kill-stay: kill the word without moving the point,
- M-t w i a -
avy-action-ispell: use ispell/flyspell to correct the word,
- M-t w y a -
avy-action-yank: yank the word at point,
- M-t w t a -
avy-action-teleport: kill the word and yank it at point,
- M-t w z a -
avy-action-zap-to-char: kill from point up to selected point.
You can customize avy-dispatch-alist to modify these actions, and also ensure that there's no
overlap with your avy-keys, if you customized them.
New avy-style setting: 'words
You can now customize:
And you'll see overlays like "by", "if", "is", "it", "my" for 2-letter sequences, and "can", "car",
"cog" for 3-letter sequences. You might find them easier to type than "hla", "lls" and "jhl". But
you will have to adjust your avy-dispatch-alist, e.g. to use only upper case characters.
avy-linum-mode
This is feature is a mix of linum-mode and ace-window-display-mode. You'll see the overlays when
you enable this mode, so that there's less context switch when you call avy-goto-line.
Restarting an avy search
Suppose you jumped to a word that starts with "a". Now you want to jump to a different word that
also starts with "a". You can use avy-resume for this.
Additionally, you can use avy-next and avy-prev to cycle between the last avy
candidates. Here's an example hydra to facilitate it:
(defhydra hydra-avy-cycle ()
("j" avy-next "next")
("k" avy-prev "prev")
("q" nil "quit"))
(global-set-key (kbd "C-M-'") 'hydra-avy-cycle/body)
Outro
Big thanks to all contributors, and I hope you enjoy the new release. Happy hacking!
11 Apr 2019
Intro
I'm constantly amazed by other people's Org workflows. Now that the weekly tips are a
thing, I see more and more cool Org configs, and I'm inspired to get more organized myself.
My own Org usage is simplistic in some areas, and quite advanced in others. While I wrote a lot of
code to manipulate Org files ( worf,
org-download, orca,
org-fu, counsel), the
amount of Org files and TODO items that I have isn't huge:
(counsel-git "org$ !log")
;; 174 items
(counsel-rg "\\* DONE|CANCELLED|TODO")
;; 8103 items
Still, that's enough to get out-of-date files: just today I dug up a file with 20 outstanding TODO
items that should have been canceled last November!
How to close 20 TODOs using a timestamp in the past
When I cancel an item, pressing tc (mnemonic for TODO-Cancel), Org mode inserts a time
stamp with the current time. However, for this file, I wanted to use October 31st 2018 instead of
the current time. Org mode already has options like org-use-last-clock-out-time-as-effective-time,
org-use-effective-time, and org-extend-today-until that manipulate the current time for
timestamps, but they didn't fit my use case.
So I've advised org-current-effective-time:
(defvar-local worf--current-effective-time nil)
(defun worf--current-effective-time (orig-fn)
(or worf--current-effective-time
(funcall orig-fn)))
(advice-add 'org-current-effective-time
:around #'worf--current-effective-time)
(defun worf-change-time ()
"Set `current-time' in the current buffer for `org-todo'.
Use `keyboard-quit' to unset it."
(interactive)
(setq worf--current-effective-time
(condition-case nil
(org-read-date t 'totime)
(quit nil))))
A few things of note here:
worf--current-effective-time is buffer-local, so that it modifies time only for the current
buffer- I re-use the awesome
org-read-date for a nice visual feedback when inputting the new time
- Instead of having a separate function to undo the current-time override, I capture the
quit
signal that C-g sends.
Outro
The above code is already part of worf and is bound to
cT. I even added it to the manual. I hope you find it useful. Happy organizing!
07 Apr 2019
Intro
Since its introduction in 2015, swiper, while nice most of the time, had two problems:
- Slow startup for large buffers.
- Candidates were lines, so if you had two or more matches on the same line, the first one was selected.
Over time, workarounds were added to address these problems.
Problem 1: slow startup
Almost right away, calling font-lock-ensure was limited to only small enough buffers.
In 2016, counsel-grep-or-swiper was introduced. It
uses an external process (grep) to search through large files.
In 2017, I found ripgrep, which does a better
job than grep for searching one file:
(setq counsel-grep-base-command
"rg -i -M 120 --no-heading --line-number --color never %s %s")
The advantage here is that the search can be performed on very large files. The trade-off is that we
have to type in at least 3 characters before we send it to the external process. Otherwise, when the
process returns a lot of results, Emacs will lag while receiving all that output.
Problem 2: candidates are lines
In 2015, swiper-avy was added, which could also be
used as a workaround for many candidates on a single line. Press C-' to visually select
any candidate on screen using avy.
Enter swiper-isearch
Finally, less than a week ago, I wrote swiper-isearch to fix #1931.
Differences from the previous commands:
Every candidate is a point position and not a line. The UX of going from one candidate to the next
is finally isearch-like, I enjoy it a lot.
Unlike swiper, no line numbers are added to the candidates. This allows it to be as fast as
anzu.
Unlike counsel-grep, no external process is used. So you get feedback even after inputting a
single char.
I like it a lot so far, enough to make it my default search:
(global-set-key (kbd "C-s") 'swiper-isearch)
Outro
Try out swiper-isearch, see if it can replace swiper for you; counsel-grep-or-swiper still has
its place, I think. Happy hacking!
PS. Thanks to everyone who supports me on Liberapay and
Patreon!
PPS. Thanks to everyone who contributes issues and patches!
